deepseek-ai / DeepSeek-R1【2025】
1. Introduction
DeepSeek has unveiled its first-generation reasoning models—DeepSeek‑R1‑Zero and DeepSeek‑R1—marking a shift toward logic-driven AI architectures. DeepSeek‑R1‑Zero leverages pure reinforcement learning (RL) directly on the base network, forgoing the common approach of supervised fine-tuning (SFT). As a result, it demonstrated emergent chain-of-thought reasoning, self-reflection, and self-verification. However, the model also displayed issues with readability, repetition, and intermittent language mixing .

To refine these capabilities, DeepSeek introduced DeepSeek‑R1, which combines cold-start supervised data, dual-stage RL, and polished fine-tuning. This model rivals OpenAI‑o1‑1217 in math, code, and general reasoning. Accompanying the main releases, six dense distilled models (1.5–70B, based on Qwen2.5 and LLaMA) have been made open source, with the Qwen‑32B variant surpassing o1‑mini benchmarks .
2. DeepSeek‑R1‑Zero: Pure RL Unlocks Reasoning
2.1 Training Framework
DeepSeek‑R1‑Zero was trained with Group Relative Policy Optimization (GRPO)—a strategy in which sampled model outputs are ranked and used to reinforce the best reasoning trajectories. Notably, no labeled data or SFT was used, making it the first open-source LLM demonstrating reasoning purely through RL .
2.2 Emergent Reasoning Patterns
Trained through self-guided RL, R1‑Zero developed:
Chain-of-thought (CoT) sequences with internal reflection
Self-verification steps mid-reasoning
“Aha moments” where mistakes are self-corrected
This breakthrough challenges the assumption that explicit human guidance is essential for CoT abilities.
2.3 Limitations of Zero-RL
Despite its strengths, R1‑Zero had practical challenges:
Unreadable reasoning due to token-level noise
Content looping and redundancy
Language mixing—especially mid-thought changes between Chinese and English
These issues underscored the need for a refined, user-ready iteration.
3. DeepSeek‑R1: Multi-Stage Pipeline for Coherent Reasoning
DeepSeek-R1 Models
| Model | #Total Params | #Activated Params | Context Length | Download |
|---|---|---|---|---|
| DeepSeek-R1-Zero | 671B | 37B | 128K | 🤗 HuggingFace |
| DeepSeek-R1 | 671B | 37B | 128K |
DeepSeek-R1-Distill Models
| Model | Base Model | Download |
|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | Qwen2.5-Math-1.5B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Qwen-7B | Qwen2.5-Math-7B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Llama-8B | Llama-3.1-8B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Qwen-14B | Qwen2.5-14B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Qwen-32B | Qwen2.5-32B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Llama-70B | Llama-3.3-70B-Instruct | 🤗 HuggingFace |
DeepSeek-R1-Distill models are fine-tuned based on open-source models, using samples generated by DeepSeek-R1. We slightly change their configs and tokenizers. Please use our setting to run these models.
3.1 Integrated Training Stages
To refine zero-RL capabilities, DeepSeek employed a multi-stage pipeline for DeepSeek‑R1:
Cold-start SFT: introduces clarity via supervised text
First-stage RL: emphasizes chain-of-thought logic
Second-stage RL: aligns output with human preference
Final SFT polish: enhances fluency and removes artifacts
This method balances emergent reasoning and user-readability.
3.2 Benchmarking Performance
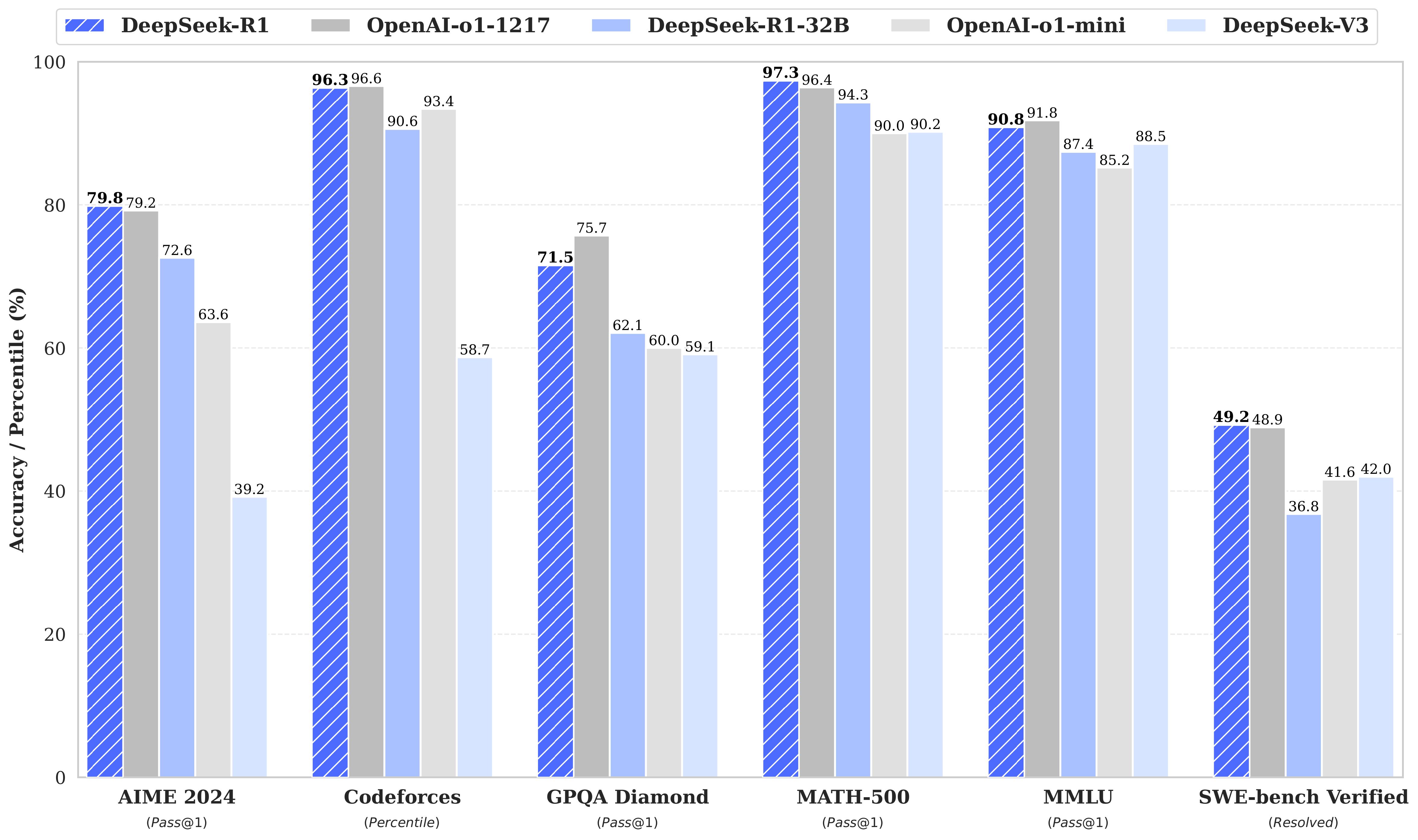
DeepSeek‑R1 matches or exceeds OpenAI o1‑1217:
| Task | DeepSeek‑R1 Score | o1‑1217 Score |
|---|---|---|
| AIME 2024 | 79.8% | ~79.2% |
| MATH‑500 | 97.3% | ~97.3% |
| Codeforces | Elo 2029 (96.3%) | ~2020 (~96%) |
| MMLU | 90.8% | 91.8% |
It also exceeds OpenAI's codes in dense-model formats and cost efficiency .
4. Distillation: Scaling Down Without Losing Logic
4.1 Distillation Approach
Using outputs from DeepSeek‑R1, the team distilled reasoning into models ranging from 1.5B to 70B parameters (Qwen2.5 & LLaMA). These dense models uphold robust reasoning in lightweight formats .
4.2 Benchmark Highlights
Qwen‑1.5B: 83.9% on MATH-500
Qwen‑14B: 93.9% on MATH-500
Qwen‑32B: 72.6% (AIME), 94.3% (MATH), 57.2% (LiveCode)
Llama‑70B: 94.5% (MATH), 86.7% (AIME), 57.5% (LiveCode)
Notably, Qwen‑32B surpasses OpenAI‑o1‑mini, and Llama‑70B performs on par or better on coding tasks .
5. Technical Architecture & Innovations
5.1 Mixture-of-Experts Model
DeepSeek‑R1 is built on a 671B parameter MoE architecture, where inference uses ~37B per token—balancing speed and reasoning capacity. Distilled models serve those requiring simpler deployment .
5.2 GRPO-Based Reasoning Training
GRPO compares output samples for coherence and correctness, allowing the model to learn reasoning patterns without explicit chain-of-thought labels .
5.3 Thought Transparency
DeepSeek employs <think>…</think> tags to expose internal reasoning, followed by <answer>…</answer> blocks—aligned with how human reasoning frameworks work .
6. Cost Efficiency & Open-Sourcing Impact
6.1 Training Cost
DeepSeek reports training for about US $6M over two months—dramatically lower than the hundreds of millions spent by some competitors .
6.2 Accessibility
All model weights and APIs are released under the MIT license, empowering community-driven research and distillation. This open-access approach positions DeepSeek as a serious competitor to proprietary giants .
6.3 Open‑Source Ecosystem Catalysts
Follow-up initiatives like Open‑Reasoner‑Zero scale the technique further, and the release of 1.4M reasoning dataset supports broader adoption .
7. Broader Implications & Future Directions
7.1 Emergence of Reasoning via RL
The success of DeepSeek‑R1‑Zero validates that reasoning can develop through RL alone—prompting reevaluation of model development pipelines .
7.2 Toolkit for Developers & Educators
Visible chain-of-thought outputs boost interpretability and offer a foundation for education, code assistants, and research .
7.3 Towards Multi-Modal Agents
Future models may extend to vision, speech, and symbolic reasoning—all under RL‑first architectures.
7.4 Responsible AI & Safety
Transparency in reasoning enables better oversight, essential for deployment in sensitive sectors—especially when combined with human-in-loop systems .
8. Conclusion
DeepSeek’s R1 family represents a quantum leap in reasoning-first LLMs:
DeepSeek‑R1‑Zero proves chain-of-thought can emerge without supervision.
DeepSeek‑R1 refines this reasoning into robust, human-readable outputs rivaling top proprietary models.
Distilled models democratize reasoning power across diverse hardware platforms.
With transparent reasoning, open-source access, and cost-effective RL training, DeepSeek is spearheading a new era in intelligent AI. Whether in research, education, or industry, these models offer unprecedented tools for reasoning-centric applications—an evolution few thought possible in such short order.








